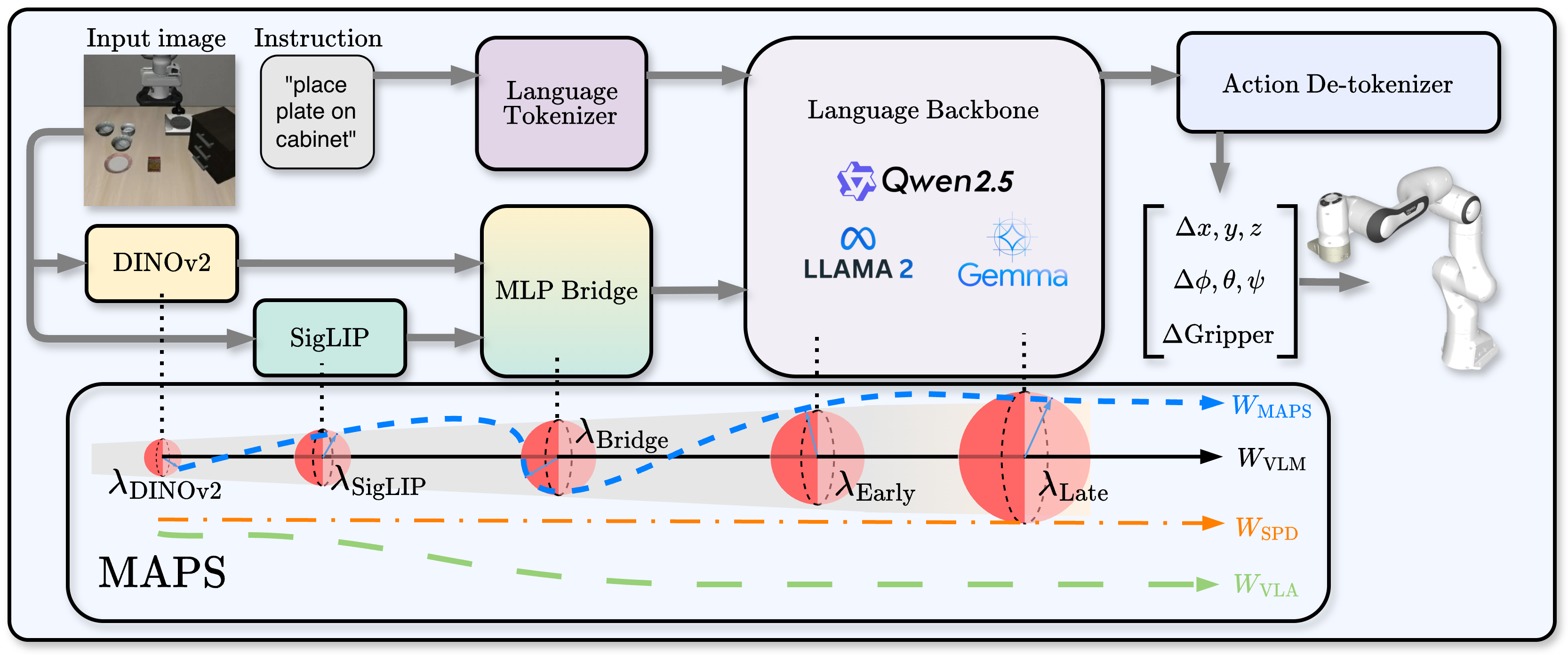
Vision-Language-Action (VLA) models inherit strong priors from pretrained Vision-Language Models (VLMs), but naïve fine-tuning often disrupts these representations and harms generalization. Existing fixes -- freezing modules or applying uniform regularization -- either overconstrain adaptation or ignore the differing roles of VLA components.
We present MAPS (Module-Wise Proximity Scheduling), the first robust fine-tuning framework for VLAs. Through systematic analysis, we uncover an empirical order in which proximity constraints should be relaxed to balance stability and flexibility. MAPS linearly schedules this relaxation, enabling visual encoders to stay close to their pretrained priors while action-oriented language layers adapt more freely. MAPS introduces no additional parameters or data, and can be seamlessly integrated into existing VLAs.
Across MiniVLA-VQ, MiniVLA-OFT, OpenVLA-OFT, and challenging benchmarks such as SimplerEnv, CALVIN, LIBERO, as well as real-world evaluations on the Franka Emika Panda platform, MAPS consistently boosts both in-distribution and out-of-distribution performance (up to +30%). Our findings highlight empirically guided proximity to pretrained VLMs as a simple yet powerful principle for preserving broad generalization in VLM-to-VLA transfer.